The Poseidon poster at ISBA 2023
The biennial meeting of the International Society for Biomolecular Archaeology (ISBA) is one of the key conferences for human archaeogenetic research. This years meeting, ISBA2023 was set to take place from 13th to 16th September in the city of Tartu in Estonia and entitled “New Horizons in Biomolecular Archaeology”. Naturally we decided to present Poseidon there to its core user group: practitioners in the field of archaeogenetics.
We applied with an ambitious abstract (the full text is available at the bottom of this post) and were awarded a poster. Below we share what we came up with. We tried to explain what motivates us to work on Poseidon and which components of the framework are already available. This includes the package format specification, the software tools, the public archives and the Minotaur workflow.
Thiseas C. Lamnidis and I finally presented the poster as the result of collaborative work with Ayshin Ghalichi, Dhananjaya B. A. Mudiyanselage, Wolfgang Haak and Stephan Schiffels in Tartu.
You can download the complete poster in .pdf format here.


Abstract
Poseidon – Powerful and FAIR archaeogenetic genotype data management
The increase in ancient human DNA data requires robust yet flexible solutions to store and distribute it. While raw sequencing data is generally shared in large archives (e.g. ENA or SRA), no such standard exists for derived genotype data and contextual, spatiotemporal information. This raises concrete issues:
- Ancient individuals only constitute meaningful observations if their spatiotemporal provenience is known. Current practice renders it difficult to maintain the connection between archaeological context and sampled genomic data.
- Specific results can only be reproduced with genotypes. Current practice does not include their publication.
- Meta-analyses involving large amounts of data require tedious curation. Available public datasets have high key-person-risk, lag behind and are not well machine-readable.
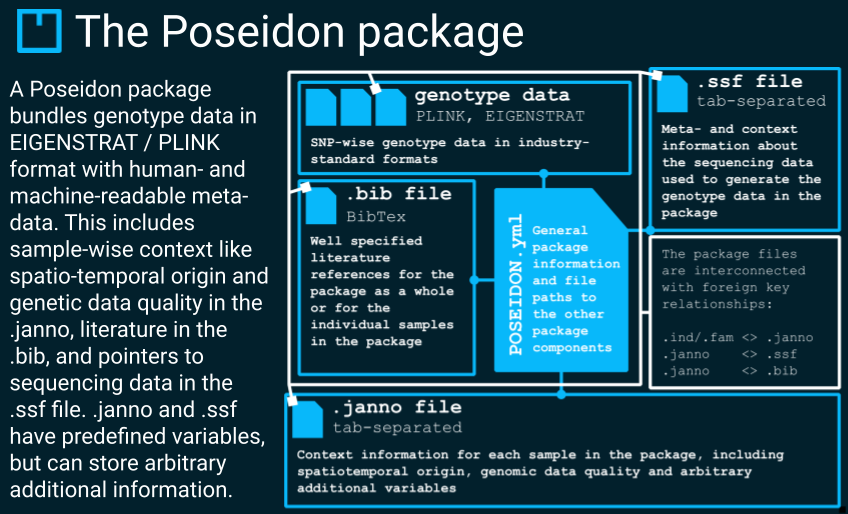
To tackle these issues we present Poseidon, a computational framework including an open data format, software, and community-maintained archives to enable standardised and FAIR handling of archaeogenetic data. A Poseidon package bundles genotypes in industry-standard formats with human- and machine-readable context data, storing sample-wise information on spatiotemporal origin and genetic data quality. Through collective effort we already prepared 100+ packages for published studies in an open online repository.
In our talk we want to specifically highlight two components of the framework:
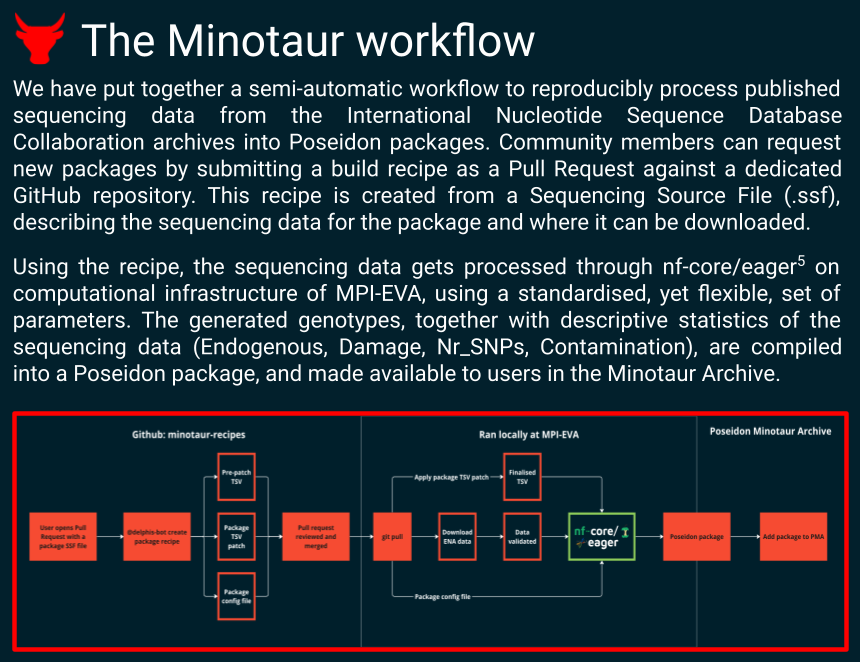
- A computational platform to process raw sequencing data directly from archive data (e.g. ENA), with a public interface for package curators to control processing parameters. Infrastructure will be provided by MPI-EVA, with community access and continuous integration provided via GitHub.
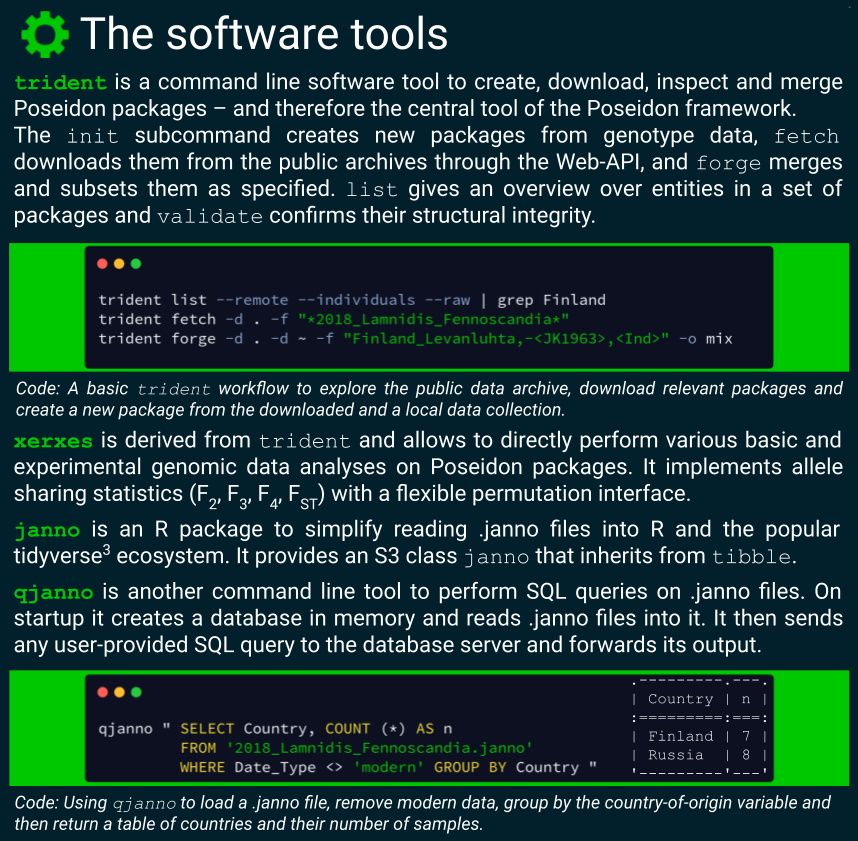
- Command line software for package validation, manipulation and analysis. Validating structural integrity is a core task to honour the FAIR promise. The reliable structure then allows for advanced stream processing and co-analysis of genomic and contextual information.